
Introduction: From Paper Pages to Digital Worksheets
If you have ever tried to reuse a textbook or test PDF, you know the challenge. Diagrams get distorted, equations turn unreadable, and formatting disappears.
We built a platform that fixes this problem. It converts educational PDFs into clean, structured problem sets that are ready for digital learning, grading, or publishing.
Our AI does not just read the page. It understands it.
If you want a step by step walkthrough of turning PDF worksheets into digital assignments, see our guide on how to turn your PDF worksheets into auto graded digital assignments
Why Educational PDF Extraction Is Different
Educational content is not like ordinary text.
Each page combines:
- Questions connected to figures
- Equations written inside paragraphs
- Formatting that adds meaning
Most PDF tools flatten this structure, turning rich learning materials into plain text and scattered images.
Our system keeps everything connected. It understands that a figure belongs to a question, and that bold or underlined words carry purpose.
What Our Platform Extracts and Preserves
1. Figures and Visuals
Graphs, charts, number lines, tables, and geometry diagrams are extracted clearly with labels, axes, legends, and captions preserved.
2. Text and Math
All text is captured in the correct reading order. Equations are rebuilt in LaTeX so they render perfectly and can be used in grading systems.
3. Formatting and Highlights
We preserve bold, italics, underline, highlights, lists, superscripts, subscripts, and headings.
How the Platform Works
Our system uses four AI powered engines that work together through one shared layout model:
- AI Page Reader – Understands page structure and identifies where questions, figures, and tables appear and how they relate.
- Vision Extraction Engine – Converts visual elements into precise data based figures while preserving their meaning.
- Text and Math Engine – Extracts all text, reading order, and math equations in editable formats.
- Linkage and Organizer – Keeps everything linked so relationships remain intact.
The result is a digital version that looks and behaves like the original, only smarter.
Deep Dive: How We Extract Figures
Our Vision Extraction Pipeline treats every diagram as information, not decoration. It transforms scanned pages into precise, labeled figures that are ready to use.
Under the hood we pair a large language model for layout reasoning and caption linking with OpenCV for image cleanup and geometry processing and Tesseract for optical character recognition inside figures and labels. The large language model helps associate figures with nearby questions and captions, validate labels, and recover missing context.
Visual Extraction Process
- Clean the page and remove noise, shadows, and blur.
- Repair broken lines so shapes and axes are continuous.
- Detect meaningful regions such as graphs, charts, and tables.
- Remove stray marks and background artifacts.
- Combine axes, labels, and legends into complete figures.
- Preserve useful margins so nothing is accidentally cropped.
- Respect surrounding text and separate it cleanly.
- Identify multiple visuals and save each as its own asset.
Deep Dive: How We Extract Text and Math
1. Reading Order and Layout
We detect paragraphs, lists, headings, question blocks, and captions so the digital flow matches the printed layout.
2. Math Reconstruction
We detect inline and display math and rebuild it using LaTeX. This enables:
- Sharp rendering at any zoom level
- Easy editing or updating of equations
- Automated grading and answer checking
3. Format Preservation
In educational materials, formatting carries meaning. Bold indicates key ideas, italics signal emphasis, and highlights mark focus. We retain every one of these details.
The examples below show LaTeX equations rebuilt cleanly, tables recovered with rows and columns, and figures extracted with axes, labels, and captions.
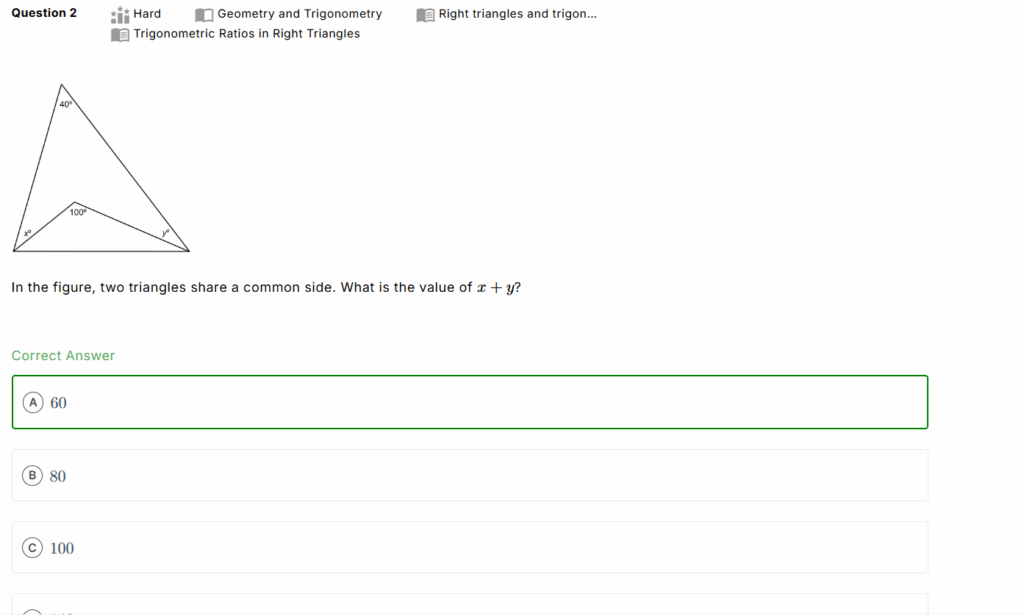


Why Our Approach Works Better
We preserve what matters. Every tick mark, label, and formula remains accurate.
We avoid over trimming. When boundaries are uncertain, we include extra context instead of losing valuable information.
We designed it modularly. Each engine can evolve independently so the system adapts easily to new document types and use cases.
Conclusion: Structured Content Ready to Use
We do not just extract documents. We rebuild them intelligently so figures, math, and text come out structured, linked, and ready for immediate use:
- Practice sets, quizzes, and full length tests — all automatically graded
- Interactive question banks that students can explore during self paced learning
No cleanup required. No manual retyping. Just clean, structured content ready to use.
You can also review, edit, or approve every extracted question and figure before publishing to ensure full quality control.
Whether you are digitizing older problem sets or creating interactive lessons, this extraction approach helps you move faster. We turn PDFs into problem sets that actually work.
Ready to see it in action
Contact us to learn how this technology can power your next generation of digital learning tools.
We support passage based and non passage items across K to 12 and test prep. Formats include multiple choice, numeric entry and fill in the blank.
Equations are rebuilt in LaTeX and render cleanly. Diagrams keep axes, ticks, labels, and captions. You can review and approve before publishing.
We use a large language model for layout reasoning along with OpenCV for image cleanup and geometry and Tesseract for text inside figures and labels.
Yes. Tables retain rows and columns and charts keep axes, legends, and labels so they are ready to use in digital worksheets.
You can fix it instantly with the built in snipping tool. Capture the correct region, replace the image, and save without leaving the workflow.
Yes. Practice sets, quizzes, and full length tests are graded automatically. You can review scores and add comments.
Yes. You can review, edit, or approve each question, figure, and caption before it goes live.
Documents are processed in a secure environment.We do not share your content.
It can read some clear handwriting but printed text works best. For heavy handwritten content we recommend manual review.
Still have questions
See our full FAQ page for policies, pricing, and troubleshooting: https://mentomind.ai/faqs/


